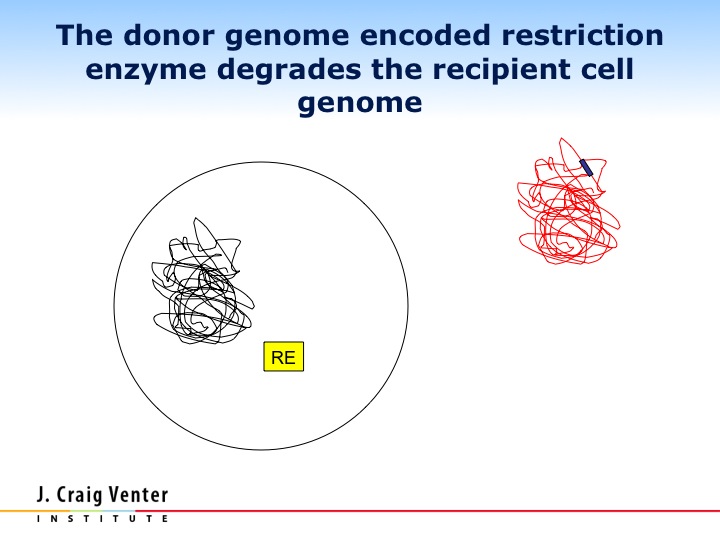
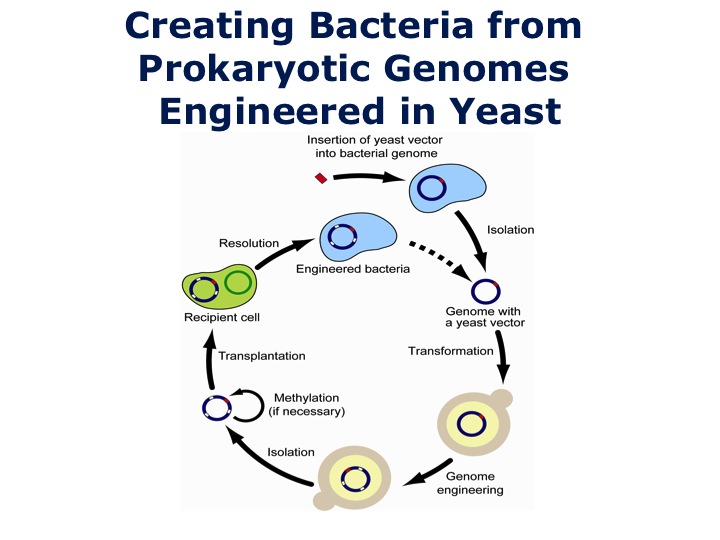
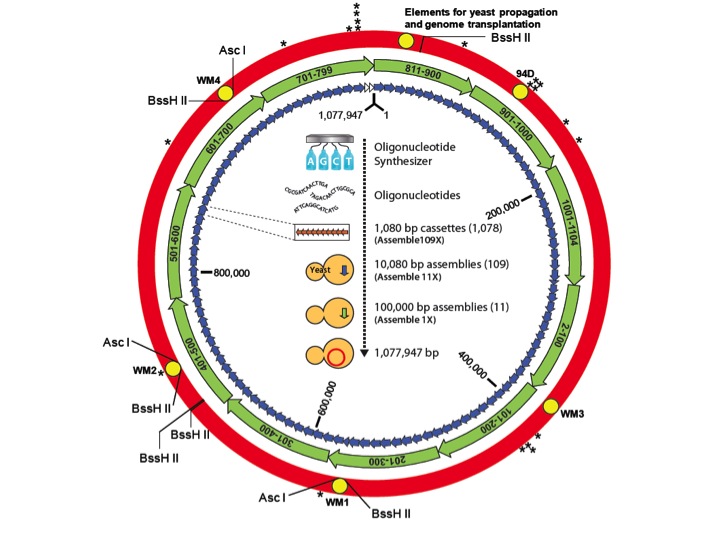
PURPOSE OF EDUCATION
Well, we could ask ourselves what the purpose of an educational system is and there are sharp differences on this matter. Now, there's the traditional interpretation that comes from the Enlightenment which holds that the highest goal in life is to inquire and create, to search the riches of the past, and try to internalize the parts of them that are significant to you and carry that quest for understanding further in your own way.
The purpose of education from that point of view is just to help people determine how to learn on their own. It's you, the learner, who is going to achieve in the course of education. It's really up to you what you'll master, where you'll go, how you'll use it. How you'll go on to produce something new and exciting for yourself, maybe for others. That's one concept of education.
(2:00)Now the other concept is essentially indoctrination. People have the idea that from childhood young people have to be placed into a framework in which they'll follow orders, accept existing frameworks, and not challenge and so. And this is often quite explicit. For example, after the activism of the 1960s, there was great concern across much of the educated spectrum that young people were just getting too free and independent, that the country was becoming too democratic and so on. And in fact There is an important study on what's called the crisis of democracy--too much democracy-- arguing that there are, claiming that there are certain insitutions responsible for the indoctrination of the young--that's their phrase-- and they're not doing their job properly. That's schools, universities, churches---we have to change them so that they carry out the job of indoctrination and control more effectively.
That's actually coming from the liberal internationalists' end of the spectrum of educated opinion. In fact, since that time there have been many measures taken to try to turn the educational system towards more control, more indoctrination, more vocational training. Imposing a debt which traps students--young people--into a life of conformity and so on.
That's the exact opposite of what I referred to as the tradition that comes out of the enlightenment. There's a constant struggle between those. In the colleges and the schools, do you train for passing tests? Or do you train for creative inquiry? Pursuing interests that are aroused by material that's presented, you want to pursue either on your own or in cooperation with others.
And this goes all the way through up to graduate school and research. Just two different ways of looking at the world. When you get to, say, a research institution like the one we're now in, at the graduate level, it essentially follows the enlightment tradition. In fact, science couldn't progress unless it was based on inculcation of the urge to challenge, to question doctrine, question authority, search for alternatives, use your imagination freely under your own impulses.
Cooperative work with others is constant as you can see just by walking down the halls. That's my view of what an educational system should be like down to kindergarten. But there certainly are powerful structures in society which would prefer people to be indoctrinated, to conform, to not ask too many questions, to be obedient, to fulfill the roles that are assigned to you and not try to shake systems of power and authority.
Those are choices we have to make, either as people, wherever we stand in the educational system. As students, as teachers, as people on the outside trying to help shape it in the direction that we think it ought to go.
IMPACT OF TECHNOLOGY
Well there certainly has been a very substantial growth in new technology--technology of communication, information, access interchange. It's surely a major change in the nature of the culture and society. We should bear in mind that the technological changes that are taking place now, while they're significant, probably come nowhere near having as much impact as technological advances of, say, a century ago plus or minus.
Let's take just communication. The shift from a typewriter to a computer or a telephone to email is significant. But it doesn't begin to compare with a shift from a sailing vessel to a telegraph. The time that that cut down in communication between England and the United States was extraordinary as compared with the changes taking place now. The same is true of other kinds of technology. The introduction of plumbing, widespread plumbing in the cities had a huge effect on health, much more than the discovery of antibiotics. So the changes are real and significant, but we should recognize that others have taken place which in many ways were more dramatic.
As far as the technology itself and education is concerned, technology is basically neutral. It's kind of like a hammer. The hammer doesn't care whether you use it to build a house or whether a torturer uses it to crush somebody's skull. A hammer can do either. Same with modern technology, say, the internet, and so on. The internet is extremely valuable if you know what you're looking for. I use it all the time for research, I'm sure everyone does. If you know the kind of what you're looking for, you have a kind of framework of understanding which directs you through particular things, and lets you sideline lots of others. Then this can be a very valuable tool.
Of course, you always have to be willing to ask "Is my framework the right one?" "Maybe I have to modify it." "Maybe if there's something I look at that questions it, I should rethink how I'm looking at things." But you can't pursue any kind of inquiry without a pretty relatively clear framework that's directing your search and helping you choose what's significant and what isn't. What can be put aside, what ought to be pursued, what ought to be challenged, what ought to be developed and so on.
You can't expect somebody to become a biologist by giving them access to the Harvard University biology library and say, "Just look through it." That'll give them nothing. The internet is the same except magnified enormously. If you don't understand or know what you're looking for, if you don't have some kind of conception of what matters--always, of course, with the proviso that you're willing to question and see if it's going in the wrong direction--if you don't have that, exploring the internet is just picking out random factoids that don't mean anything. So, behind any significant use of contemporary technology--the internet, communications systems, graphics, whatever it may be--behind, unless behind it is a well constructed, directive, conceptual apparatus, it is very unlikely to be helpful.
It may turn out to be harmful. For example, random exploration through the internet turns out to be a cult generator. You pick up a factoid here, and a factoid there and somebody else reinforces it. All of sudden you have some [crazed] picture which has some factual basis but nothing to do with the world. You have to know how to evaluate, interpret, and understand. Say biology again. The person who wins the Nobel prize in biology is not the person who read the most journal articles and took the most notes on them. It's the person who knew what to look for. And cultivating that capacity to seek what's significant--always willing to question whether you're on the right track--that's what education is going to be about, Whether it's using computers and the internet or pencil and paper and books.
(11:48) COST OR INVESTMENT
Well, education is discussed in terms of whether it's a worthwhile investment. Does it create human capital that can be used for economic growth and so on. And it's a very strange, kind of, very distorting way to even pose the question, I think.
Do we want to have a society of free, creative, independent individuals, able to appreciate and to gain from the cultural achievements of the past, and to add to them? Do we want that? Or do we want people who can increase GDP? It's not necessarily the same, they're not the same thing. An education of the kind that, say, Bertrand Russell, John Dewey and others talked about, that's a value in itself. Whatever impact it has in the society, it's a value because it helps create better human beings. After all, that's what an educational system should be for.
On the other hand, if you want to look at it in terms of costs and benefits, take the new technology that we were just talking about, where did that come from? Well, actually a lot of it was developed right where we're sitting, down below where we now are was a major laboratory back in the 1950s, where i was employed in fact. Which had lots of scientists, engineers, people of all kinds of interests--philosophers, others. Who were working on developing the basic character and even the basic tools of the technology that has now come.
Computers and the internet for example, were pretty much in the public sector for decades, funded in places like this, where people were exploring new possibilities that were mostly unthought of, unheard of at the time. Some of them worked, some didn't. The ones that worked were finally converted into tools that people could use. Now that's the way scientific progress takes place. It's the way that cultural progress takes place generally.
(14:24) Classical artists, for example, came out of a tradition of craftsmanship that was developed over long periods with master artisans, with others. Sometimes you can rise on their shoulders and create new, marvelous things. But it doesn't come from nowhere. If there isn't a lively cultural and educational system which is geared towards encouraging creative exploration, independence of thought, willingness to challenge, cross frontiers, to challenge accepted beliefs and so on. If you don't have that, you're not going to get the technology that can lead to economic gains. Though that I don't think is the prime purpose of cultural enrichment in education as a part of it.
(15:44) ASSESSMENT VS AUTONOMY
There is, in the recent period particularly, an increasing shaping of education from the early ages on towards passing examinations. Taking tests can be of some use, both for the person who is taking the test--seeing what I know, and where I am, and what I would achieve, what [I'm having]--and for instructors--what should be changed and improved in developing the course of instruction.
But beyond that, they don't really tell you very much. I mean I know for many many years, I've been on admissions committees for entry into advanced graduate programs--maybe one of the most advanced anywhere--and we of course pay some attention to test results, but really not too much. A person can do magnificently on every test and understand very little. All of us who've been through schools and colleges and universities are very familiar with this.
You can be assigned, you can be in some, say, course that you have no interest in and there's demand that you passes a test, and you can study hard for the test, and you can ace it. And a couple of weeks later you've forgotten what the topic was. I'm sure we've all had that experience. I know I have. It can be a useful device if it contributes to the constructive purposes of education.
If it's just a set of hurdles you have to cross, it can turn out to be not only meaningless, but it can divert you away from things that you want to be doing. I see this regularly when I talk to teachers. If you want an experience from a couple of weeks ago--I happened to be talking to a group which included many schoolteachers. One of them was a sixth grade teacher who teaches kids, I guess, ten or eleven or twelve, something like that. She came up to me afterwards and I'd been talking about these things and she told me of an experience that she had just had in her class. After class a little girl came up to her and said she was really interested in something that came up and she asked if the teacher could give her some ideas of how she could look into it further. And the teacher was compelled to tell her, "I'm sorry, but you can't do that, you have to study to pass this national exam that's coming, that's going to determine your future." The teacher didn't say it, "but it's going to determine my future, whether I am rehired."
The system is geared to getting the children to pass hurdles, but not to learn and understand and explore. That child would have been better off if she had been allowed to explore what she was interested in and maybe not do so well on the test about things she wasn't interested in. They'll come along when they fit into her interests and concerns.
So, I don't say that tests should be eliminated, they can be a useful educational tool. But ancillary--something that is helping improve ourselves, for instructors, and others, what we're doing--tell us where we are. Passing tests doesn't begin to compare with searching and inquiring into pursuing topics that engage us and excite us. That's far more significant than passing tests. In fact, if that's the kind of educational career that you're given the opportunity to pursue, you'll remember what you discovered.
There is a famous physicist, a world famous physicist right here at MIT who was teaching freshman courses. He once said that in his freshman course, students will ask, "What are we going to cover this semester?" And his standard answer was, "It doesn't matter what we cover, it matters what you discover."
That's right. Teaching ought to be inspiring students to discover on their own. To challenge if they don't agree. To look for alternatives if they think there are better ones. To work through the great achievements of the past and try to master them on their own because they're interested in them. If that's the way teaching is done, students will really gain from it and will not only remember what they've studied but be able to use it as a basis for going on on their own.
And again, education is really aimed at just helping students get to the point where they can learn on their own. Because that's what you're going to do for you life. Not just absorb materials that are given to you from the outside and repeat it.
Well, we could ask ourselves what the purpose of an educational system is and there are sharp differences on this matter. Now, there's the traditional interpretation that comes from the Enlightenment which holds that the highest goal in life is to inquire and create, to search the riches of the past, and try to internalize the parts of them that are significant to you and carry that quest for understanding further in your own way.
The purpose of education from that point of view is just to help people determine how to learn on their own. It's you, the learner, who is going to achieve in the course of education. It's really up to you what you'll master, where you'll go, how you'll use it. How you'll go on to produce something new and exciting for yourself, maybe for others. That's one concept of education.
(2:00)Now the other concept is essentially indoctrination. People have the idea that from childhood young people have to be placed into a framework in which they'll follow orders, accept existing frameworks, and not challenge and so. And this is often quite explicit. For example, after the activism of the 1960s, there was great concern across much of the educated spectrum that young people were just getting too free and independent, that the country was becoming too democratic and so on. And in fact There is an important study on what's called the crisis of democracy--too much democracy-- arguing that there are, claiming that there are certain insitutions responsible for the indoctrination of the young--that's their phrase-- and they're not doing their job properly. That's schools, universities, churches---we have to change them so that they carry out the job of indoctrination and control more effectively.
That's actually coming from the liberal internationalists' end of the spectrum of educated opinion. In fact, since that time there have been many measures taken to try to turn the educational system towards more control, more indoctrination, more vocational training. Imposing a debt which traps students--young people--into a life of conformity and so on.
That's the exact opposite of what I referred to as the tradition that comes out of the enlightenment. There's a constant struggle between those. In the colleges and the schools, do you train for passing tests? Or do you train for creative inquiry? Pursuing interests that are aroused by material that's presented, you want to pursue either on your own or in cooperation with others.
And this goes all the way through up to graduate school and research. Just two different ways of looking at the world. When you get to, say, a research institution like the one we're now in, at the graduate level, it essentially follows the enlightment tradition. In fact, science couldn't progress unless it was based on inculcation of the urge to challenge, to question doctrine, question authority, search for alternatives, use your imagination freely under your own impulses.
Cooperative work with others is constant as you can see just by walking down the halls. That's my view of what an educational system should be like down to kindergarten. But there certainly are powerful structures in society which would prefer people to be indoctrinated, to conform, to not ask too many questions, to be obedient, to fulfill the roles that are assigned to you and not try to shake systems of power and authority.
Those are choices we have to make, either as people, wherever we stand in the educational system. As students, as teachers, as people on the outside trying to help shape it in the direction that we think it ought to go.
IMPACT OF TECHNOLOGY
Well there certainly has been a very substantial growth in new technology--technology of communication, information, access interchange. It's surely a major change in the nature of the culture and society. We should bear in mind that the technological changes that are taking place now, while they're significant, probably come nowhere near having as much impact as technological advances of, say, a century ago plus or minus.
Let's take just communication. The shift from a typewriter to a computer or a telephone to email is significant. But it doesn't begin to compare with a shift from a sailing vessel to a telegraph. The time that that cut down in communication between England and the United States was extraordinary as compared with the changes taking place now. The same is true of other kinds of technology. The introduction of plumbing, widespread plumbing in the cities had a huge effect on health, much more than the discovery of antibiotics. So the changes are real and significant, but we should recognize that others have taken place which in many ways were more dramatic.
As far as the technology itself and education is concerned, technology is basically neutral. It's kind of like a hammer. The hammer doesn't care whether you use it to build a house or whether a torturer uses it to crush somebody's skull. A hammer can do either. Same with modern technology, say, the internet, and so on. The internet is extremely valuable if you know what you're looking for. I use it all the time for research, I'm sure everyone does. If you know the kind of what you're looking for, you have a kind of framework of understanding which directs you through particular things, and lets you sideline lots of others. Then this can be a very valuable tool.
Of course, you always have to be willing to ask "Is my framework the right one?" "Maybe I have to modify it." "Maybe if there's something I look at that questions it, I should rethink how I'm looking at things." But you can't pursue any kind of inquiry without a pretty relatively clear framework that's directing your search and helping you choose what's significant and what isn't. What can be put aside, what ought to be pursued, what ought to be challenged, what ought to be developed and so on.
You can't expect somebody to become a biologist by giving them access to the Harvard University biology library and say, "Just look through it." That'll give them nothing. The internet is the same except magnified enormously. If you don't understand or know what you're looking for, if you don't have some kind of conception of what matters--always, of course, with the proviso that you're willing to question and see if it's going in the wrong direction--if you don't have that, exploring the internet is just picking out random factoids that don't mean anything. So, behind any significant use of contemporary technology--the internet, communications systems, graphics, whatever it may be--behind, unless behind it is a well constructed, directive, conceptual apparatus, it is very unlikely to be helpful.
It may turn out to be harmful. For example, random exploration through the internet turns out to be a cult generator. You pick up a factoid here, and a factoid there and somebody else reinforces it. All of sudden you have some [crazed] picture which has some factual basis but nothing to do with the world. You have to know how to evaluate, interpret, and understand. Say biology again. The person who wins the Nobel prize in biology is not the person who read the most journal articles and took the most notes on them. It's the person who knew what to look for. And cultivating that capacity to seek what's significant--always willing to question whether you're on the right track--that's what education is going to be about, Whether it's using computers and the internet or pencil and paper and books.
(11:48) COST OR INVESTMENT
Well, education is discussed in terms of whether it's a worthwhile investment. Does it create human capital that can be used for economic growth and so on. And it's a very strange, kind of, very distorting way to even pose the question, I think.
Do we want to have a society of free, creative, independent individuals, able to appreciate and to gain from the cultural achievements of the past, and to add to them? Do we want that? Or do we want people who can increase GDP? It's not necessarily the same, they're not the same thing. An education of the kind that, say, Bertrand Russell, John Dewey and others talked about, that's a value in itself. Whatever impact it has in the society, it's a value because it helps create better human beings. After all, that's what an educational system should be for.
On the other hand, if you want to look at it in terms of costs and benefits, take the new technology that we were just talking about, where did that come from? Well, actually a lot of it was developed right where we're sitting, down below where we now are was a major laboratory back in the 1950s, where i was employed in fact. Which had lots of scientists, engineers, people of all kinds of interests--philosophers, others. Who were working on developing the basic character and even the basic tools of the technology that has now come.
Computers and the internet for example, were pretty much in the public sector for decades, funded in places like this, where people were exploring new possibilities that were mostly unthought of, unheard of at the time. Some of them worked, some didn't. The ones that worked were finally converted into tools that people could use. Now that's the way scientific progress takes place. It's the way that cultural progress takes place generally.
(14:24) Classical artists, for example, came out of a tradition of craftsmanship that was developed over long periods with master artisans, with others. Sometimes you can rise on their shoulders and create new, marvelous things. But it doesn't come from nowhere. If there isn't a lively cultural and educational system which is geared towards encouraging creative exploration, independence of thought, willingness to challenge, cross frontiers, to challenge accepted beliefs and so on. If you don't have that, you're not going to get the technology that can lead to economic gains. Though that I don't think is the prime purpose of cultural enrichment in education as a part of it.
(15:44) ASSESSMENT VS AUTONOMY
There is, in the recent period particularly, an increasing shaping of education from the early ages on towards passing examinations. Taking tests can be of some use, both for the person who is taking the test--seeing what I know, and where I am, and what I would achieve, what [I'm having]--and for instructors--what should be changed and improved in developing the course of instruction.
But beyond that, they don't really tell you very much. I mean I know for many many years, I've been on admissions committees for entry into advanced graduate programs--maybe one of the most advanced anywhere--and we of course pay some attention to test results, but really not too much. A person can do magnificently on every test and understand very little. All of us who've been through schools and colleges and universities are very familiar with this.
You can be assigned, you can be in some, say, course that you have no interest in and there's demand that you passes a test, and you can study hard for the test, and you can ace it. And a couple of weeks later you've forgotten what the topic was. I'm sure we've all had that experience. I know I have. It can be a useful device if it contributes to the constructive purposes of education.
If it's just a set of hurdles you have to cross, it can turn out to be not only meaningless, but it can divert you away from things that you want to be doing. I see this regularly when I talk to teachers. If you want an experience from a couple of weeks ago--I happened to be talking to a group which included many schoolteachers. One of them was a sixth grade teacher who teaches kids, I guess, ten or eleven or twelve, something like that. She came up to me afterwards and I'd been talking about these things and she told me of an experience that she had just had in her class. After class a little girl came up to her and said she was really interested in something that came up and she asked if the teacher could give her some ideas of how she could look into it further. And the teacher was compelled to tell her, "I'm sorry, but you can't do that, you have to study to pass this national exam that's coming, that's going to determine your future." The teacher didn't say it, "but it's going to determine my future, whether I am rehired."
The system is geared to getting the children to pass hurdles, but not to learn and understand and explore. That child would have been better off if she had been allowed to explore what she was interested in and maybe not do so well on the test about things she wasn't interested in. They'll come along when they fit into her interests and concerns.
So, I don't say that tests should be eliminated, they can be a useful educational tool. But ancillary--something that is helping improve ourselves, for instructors, and others, what we're doing--tell us where we are. Passing tests doesn't begin to compare with searching and inquiring into pursuing topics that engage us and excite us. That's far more significant than passing tests. In fact, if that's the kind of educational career that you're given the opportunity to pursue, you'll remember what you discovered.
There is a famous physicist, a world famous physicist right here at MIT who was teaching freshman courses. He once said that in his freshman course, students will ask, "What are we going to cover this semester?" And his standard answer was, "It doesn't matter what we cover, it matters what you discover."
That's right. Teaching ought to be inspiring students to discover on their own. To challenge if they don't agree. To look for alternatives if they think there are better ones. To work through the great achievements of the past and try to master them on their own because they're interested in them. If that's the way teaching is done, students will really gain from it and will not only remember what they've studied but be able to use it as a basis for going on on their own.
And again, education is really aimed at just helping students get to the point where they can learn on their own. Because that's what you're going to do for you life. Not just absorb materials that are given to you from the outside and repeat it.